
Concepto de un modelo secuencial para imágenes
Imagen 
En el caso de estructurar un modelo para procesar imágenes se debe lograr condensar la información de las imágenes (alto numero de pixeles) para reconocer un limitado numero de categorías. Para ello se emplean dos tipo de acciones:
- convolución (Conv2D)
- promediación (Pooling)
Tras una o múltiples convoluciones y promediaciones se procede a ligar los puntos a un arreglo que se asocia con el pronostico a realizar:

Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)), MaxPool2D(pool_size=(2,2), strides=2), Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same'), MaxPool2D(pool_size=(2,2), strides=2), Flatten(), Dense(units=len(classes),activation='softmax'),
ID:(13784, 0)
Significado de la convolución
Imagen
La operación de convolución es analoga a la multiplicación por una matriz que corresponde a una rotación de un vector. En este sentido se puede entender las convolución como una parametrización de una rotación de la imagen a ser ajustada en el proceso de aprendizaje:
ID:(13785, 0)
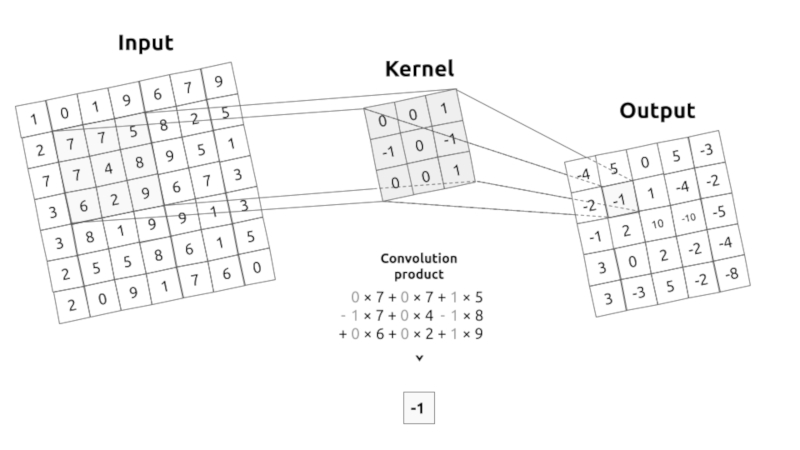
Calculo de la convolución
Imagen
La convolución corresponde a la multiplicación de elementos de una sección de la imagen por una matriz kernel cuya suma se toma como el resultado de la convolución:
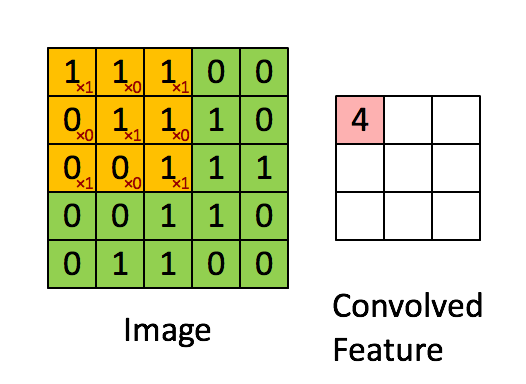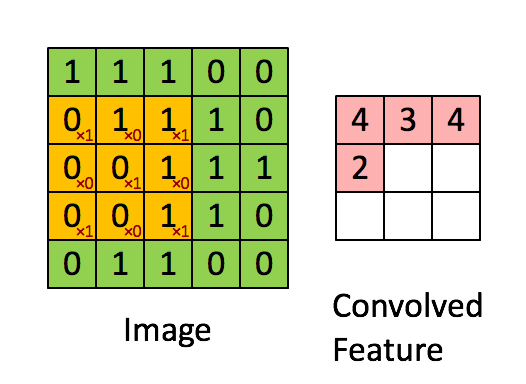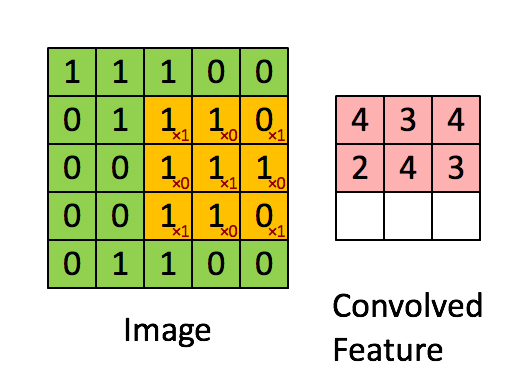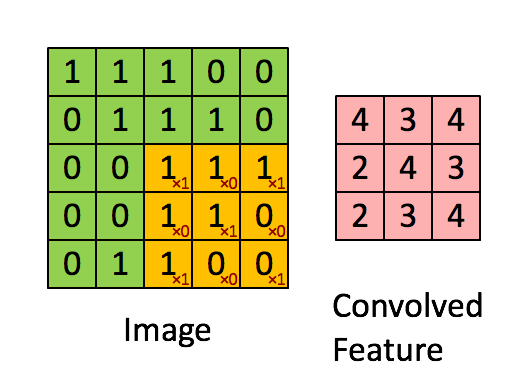
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
ID:(13786, 0)
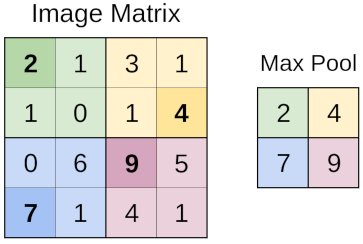
Cálculo del resumir (pooling)
Imagen
Sección de la imagen se resumen mediante el proceso de pooling, siendo uno de este tipo de proceso obtener del valor máximo (MaxPooling)
MaxPool2D(pool_size=(2,2), strides=2)
ID:(13787, 0)
Otro tipo de cálculo del resumir (pooling)
Imagen
Un método distinto de sumarización es el obtener un valor medio para una sección de la imagen (AvgPooling)

ID:(13788, 0)
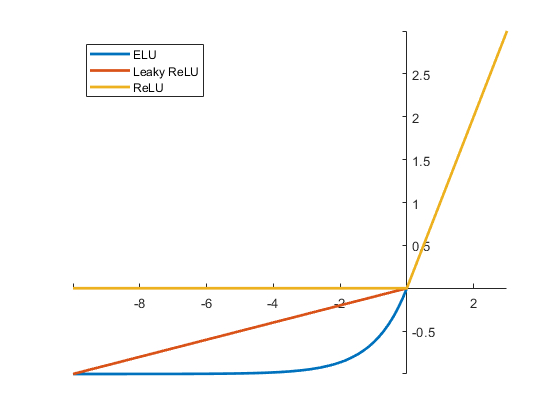
Filtro de valores (activation)
Imagen
Tras realización de la convolución se pueden filtrar los valores en función de activar o desactivar pixeles que representan la operación. Para ello se emplean funciones de activación como son por ejemplo las de
- ELU
- RELU
- WeakRELU
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
ID:(13789, 0)
Modelo secuencial de imágenes
Descripción
El modelo secuencial básico que se puede definir tiene que tener:
- un proceso de convolución sobre las imágenes iniciales
- un proceso de maxpooling para reducir el numero de puntos
- un segundo proceso de convolución sobre la imagen ya reducida
- un segundo proceso de maxpooling para nuevamente reducir el numero de puntos
- el paso a un arreglo lineal (flatten)
- una asociación al resultado buscado representado por un arreglo denso (completamente conectado a arreglo lineal anterior)
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Flatten, BatchNormalization, Conv2D, MaxPool2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix
# basic image sequential model: 2 convolutions, 2 maxpoolings, a flatten layer and a final dense layer
base_model = Sequential([
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
MaxPool2D(pool_size=(2,2), strides=2),
Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same'),
MaxPool2D(pool_size=(2,2), strides=2),
Flatten(),
Dense(units=len(classes),activation='softmax'),
])Es importante cuidar que
El tamaño de las imágenes preparadas con el comando ImageDataGenerator debe coincidir que aquel que se define bajo input_shape. En este caso es de 224 x 224 y los tres valores de los colores (RGB).
El numero de units en el plano final (dense layer) debe coincidir con el numero de clases que se están definiendo.
ID:(13755, 0)
Mostrar estructura del modelo
Descripción
base_model.summary()
Model: 'sequential'
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 224, 224, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 112, 112, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 112, 112, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 56, 56, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 200704) 0
_________________________________________________________________
dense_7 (Dense) (None, 25) 5017625
=================================================================
Total params: 5,037,017
Trainable params: 5,037,017
Non-trainable params: 0
_________________________________________________________________
ID:(13756, 0)
Compilar modelo
Descripción
Para realizar el aprendizaje es primero necesario configurar (compilar) el modelo, lo que se hace con el comando:
base_model.compile(optimizer=Adam(learning_rate=0.0001), loss='categorical_crossentropy',metrics=['accuracy'])
ID:(13757, 0)
Proceso de aprendizaje
Descripción
El modelo se entrena con la función fit en que se le indica los datos para entrenar bajo x (en este caso train_batches), los datos para validar bajo validation_data (en este caso valid_batches) en un numero de estapas llamadas epochs mostrando los resultados verbose.
# learn with the train_batches and validate with the validate_batches base_model.fit(x=train_batches, validation_data=validate_batches, epochs=10,verbose=2)
Epoch 1/10
373/373 - 78s - loss: 16.3827 - accuracy: 0.2999 - val_loss: 2.1490 - val_accuracy: 0.3582
Epoch 2/10
373/373 - 78s - loss: 0.6922 - accuracy: 0.7854 - val_loss: 2.3907 - val_accuracy: 0.4011
Epoch 3/10
373/373 - 77s - loss: 0.1305 - accuracy: 0.9734 - val_loss: 2.5407 - val_accuracy: 0.4040
Epoch 4/10
373/373 - 77s - loss: 0.0335 - accuracy: 0.9944 - val_loss: 3.0110 - val_accuracy: 0.4140
Epoch 5/10
373/373 - 77s - loss: 0.0118 - accuracy: 0.9987 - val_loss: 3.3895 - val_accuracy: 0.4011
Epoch 6/10
373/373 - 77s - loss: 0.0088 - accuracy: 0.9989 - val_loss: 3.0567 - val_accuracy: 0.4327
Epoch 7/10
373/373 - 76s - loss: 0.0023 - accuracy: 1.0000 - val_loss: 3.2413 - val_accuracy: 0.4341
Epoch 8/10
373/373 - 76s - loss: 0.0012 - accuracy: 1.0000 - val_loss: 3.4144 - val_accuracy: 0.4312
Epoch 9/10
373/373 - 77s - loss: 7.5812e-04 - accuracy: 1.0000 - val_loss: 3.4770 - val_accuracy: 0.4312
Epoch 10/10
373/373 - 77s - loss: 5.3013e-04 - accuracy: 1.0000 - val_loss: 3.5489 - val_accuracy: 0.4355
Es importante evitar el overfitting (sobreajustar) por lo que es muchas veces necesario trabajar con un numero de etapas no muy grandes.
ID:(13758, 0)
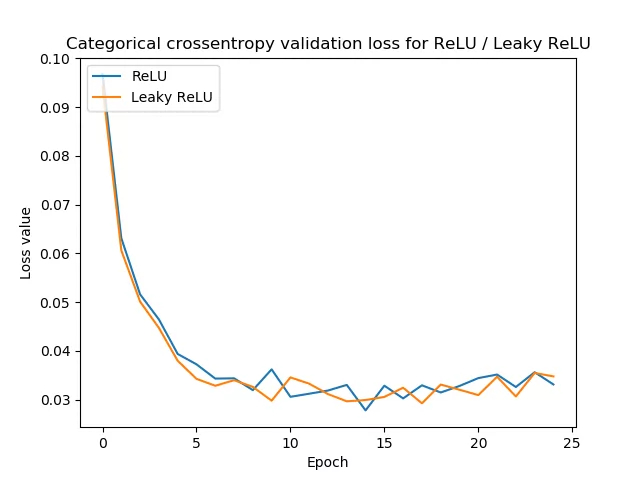
Almacenar modelos
Imagen
Para almacenar un modelo se ejecuta el comando save:
# almacenar modelos
directory = 'F:/go/face_scrapper/faces/base_model_20210721'
base_model.save('F:/go/face_scrapper/faces/base_model_20210721')
INFO:tensorflow:Assets written to: F:/go/face_scrapper/faces/base_model_20210721\assetscon lo que se genera una carpeta del nombre del directorio, el archivo del modelo y las carpetas variables y assets:
ID:(13797, 0)
Cargar modelos
Descripción
Para almacenar un modelo se ejecuta el comando save:
# cargar modelos directory = 'F:/go/face_scrapper/faces/base_model_20210721' new_model = tf.keras.models.load_model(directory)
ID:(13798, 0)