
Konzept eines sequentiellen Modells für Bilder
Bild 
Bei der Strukturierung eines Modells zur Verarbeitung von Bildern müssen die Informationen der Bilder verdichtet werden (hohe Pixelzahl), um eine begrenzte Anzahl von Kategorien zu erkennen. Dazu werden zwei Arten von Aktionen verwendet:
- Faltung (Conv2D)
- Mittelung (Pooling)
Nach einer oder mehreren Faltungen und Mittelungen werden die Punkte an eine Anordnung gebunden, die der zu erstellenden Vorhersage zugeordnet ist:

Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)), MaxPool2D(pool_size=(2,2), strides=2), Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same'), MaxPool2D(pool_size=(2,2), strides=2), Flatten(), Dense(units=len(classes),activation='softmax'),
ID:(13784, 0)
Bedeutung von Faltung
Bild
Die Faltungsoperation ist analog zur Multiplikation mit einer Matrix, die einer Drehung eines Vektors entspricht. In diesem Sinne können Faltungen als Parametrisierung einer im Lernprozess anzupassenden Drehung des Bildes verstanden werden:
ID:(13785, 0)
Berechnung der Faltung
Bild
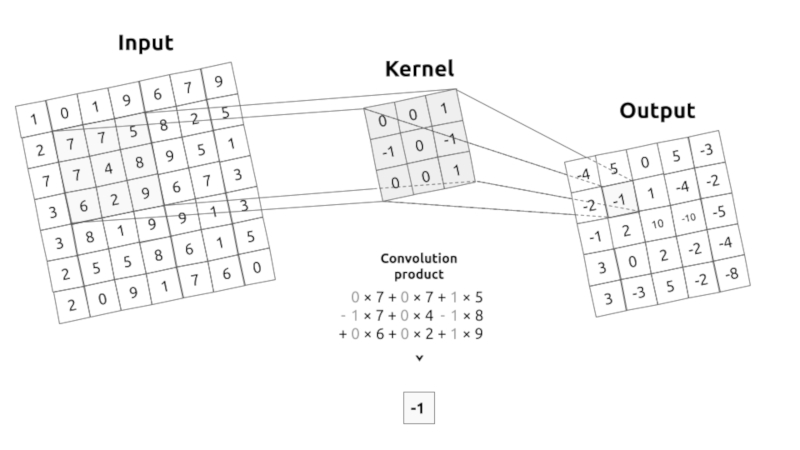
Die Faltung entspricht der Multiplikation von Elementen eines Bildausschnitts mit einer Kernelmatrix, deren Summe als Ergebnis der Faltung gebildet wird:
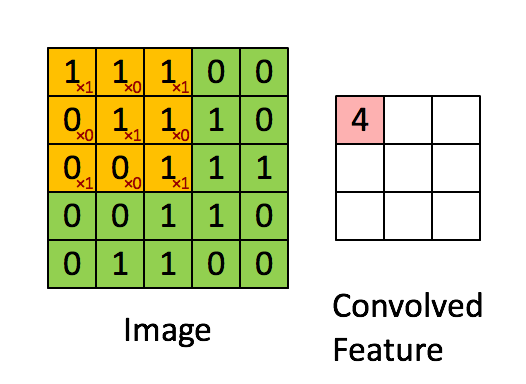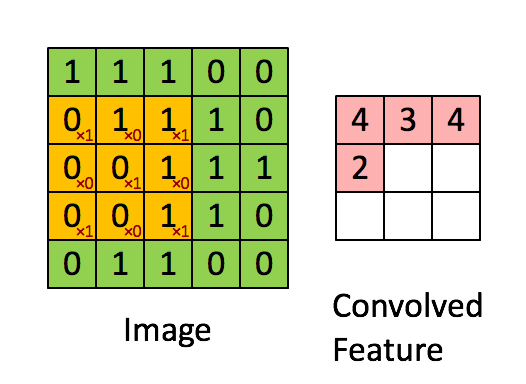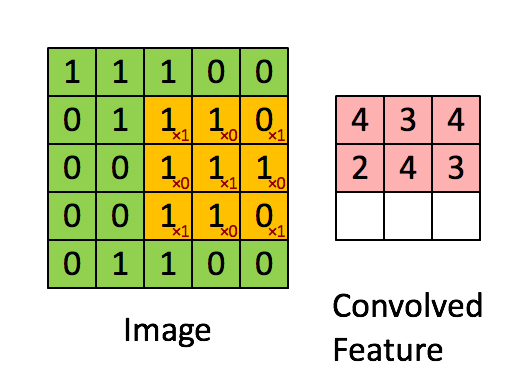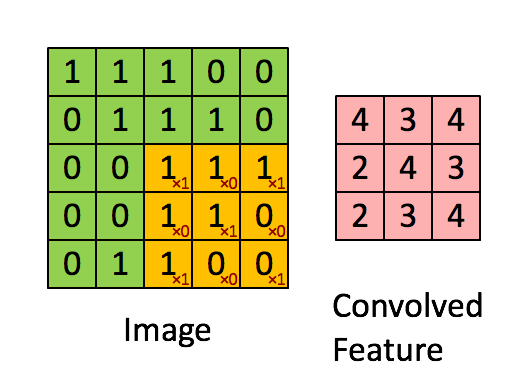
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
ID:(13786, 0)
Berechnung zusammenfassen (pooling)
Bild
Bildausschnitte werden durch den Pooling-Prozess zusammengefasst, wobei einer dieser Prozesstypen darin besteht, den Maximalwert zu erhalten (MaxPooling).
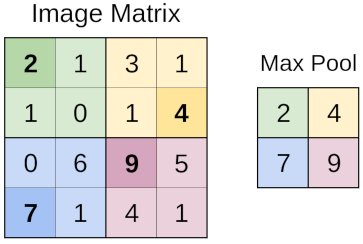
MaxPool2D(pool_size=(2,2), strides=2)
ID:(13787, 0)
Eine andere Art der Zusammenfassung (pooling)
Bild
Eine andere Methode der Zusammenfassung besteht darin, einen Durchschnittswert für einen Bildausschnitt zu erhalten (AvgPooling).

ID:(13788, 0)
Wertefilter (activation)
Bild
Nachdem die Faltung durchgeführt wurde, können die Werte basierend auf dem Aktivieren oder Deaktivieren der Pixel, die die Operation darstellen, gefiltert werden. Dazu werden Aktivierungsfunktionen verwendet, wie die von those
- ELU
- RELU
- WeakRELU
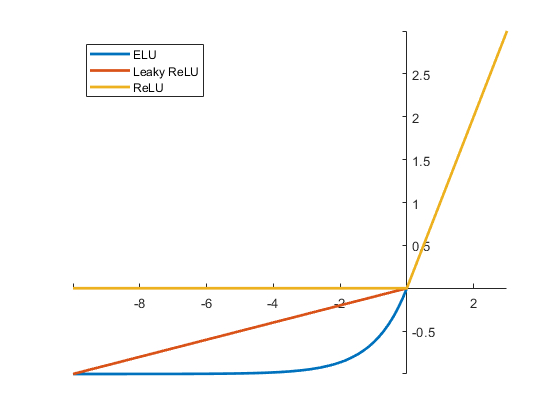
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
ID:(13789, 0)
Bildsequenzielles Modell
Beschreibung
Das grundlegende sequentielle Modell, das definiert werden kann, muss Folgendes aufweisen:
- ein Faltungsprozess der Ausgangsbilder
- ein Maxpooling-Prozess, um die Anzahl der Punkte zu reduzieren
- ein zweiter Faltungsprozess auf dem bereits verkleinerten Bild
- ein zweiter Maxpooling-Prozess um die Punktzahl wieder zu reduzieren
- der Übergang zu einem Line-Array (Flatten)
- eine Assoziation zum gewünschten Ergebnis, dargestellt durch ein dichtes Array (vollständig mit dem vorherigen Line-Array verbunden)
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Flatten, BatchNormalization, Conv2D, MaxPool2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix
# basic image sequential model: 2 convolutions, 2 maxpoolings, a flatten layer and a final dense layer
base_model = Sequential([
Conv2D(filters=32, kernel_size=(3,3), activation='relu', padding='same',input_shape=(224,224,3)),
MaxPool2D(pool_size=(2,2), strides=2),
Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same'),
MaxPool2D(pool_size=(2,2), strides=2),
Flatten(),
Dense(units=len(classes),activation='softmax'),
])Es ist wichtig darauf zu achten, dass
Die Größe der mit dem ImageDataGenerator-Befehl erstellten Bilder muss mit der unter input_shape definierten übereinstimmen. In diesem Fall sind es 224 x 224 und die drei Farbwerte (RGB).
Die Anzahl der units in der letzten Ebene (dichte Schicht) muss mit der Anzahl der zu definierenden Klassen übereinstimmen.
ID:(13755, 0)
Modellstruktur anzeigen
Beschreibung
base_model.summary()
Model: 'sequential'
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 224, 224, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 112, 112, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 112, 112, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 56, 56, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 200704) 0
_________________________________________________________________
dense_7 (Dense) (None, 25) 5017625
=================================================================
Total params: 5,037,017
Trainable params: 5,037,017
Non-trainable params: 0
_________________________________________________________________
ID:(13756, 0)
Modell erstellen
Beschreibung
Um das Lernen durchzuführen, muss zunächst das Modell konfiguriert (kompiliert) werden, was mit dem Befehl erfolgt:
base_model.compile(optimizer=Adam(learning_rate=0.0001), loss='categorical_crossentropy',metrics=['accuracy'])
ID:(13757, 0)
Lernprozess
Beschreibung
Das Modell wird mit der Funktion fit trainiert, in der die zu trainierenden Daten unter x (in diesem Fall train_batches), die zu validierenden Daten unter validation_data angegeben werden (in diesem Fall valid_batches) in einer Reihe von Phasen, die als epochs bezeichnet werden und die Ergebnisse verbose anzeigen.
# learn with the train_batches and validate with the validate_batches base_model.fit(x=train_batches, validation_data=validate_batches, epochs=10,verbose=2)
Epoch 1/10
373/373 - 78s - loss: 16.3827 - accuracy: 0.2999 - val_loss: 2.1490 - val_accuracy: 0.3582
Epoch 2/10
373/373 - 78s - loss: 0.6922 - accuracy: 0.7854 - val_loss: 2.3907 - val_accuracy: 0.4011
Epoch 3/10
373/373 - 77s - loss: 0.1305 - accuracy: 0.9734 - val_loss: 2.5407 - val_accuracy: 0.4040
Epoch 4/10
373/373 - 77s - loss: 0.0335 - accuracy: 0.9944 - val_loss: 3.0110 - val_accuracy: 0.4140
Epoch 5/10
373/373 - 77s - loss: 0.0118 - accuracy: 0.9987 - val_loss: 3.3895 - val_accuracy: 0.4011
Epoch 6/10
373/373 - 77s - loss: 0.0088 - accuracy: 0.9989 - val_loss: 3.0567 - val_accuracy: 0.4327
Epoch 7/10
373/373 - 76s - loss: 0.0023 - accuracy: 1.0000 - val_loss: 3.2413 - val_accuracy: 0.4341
Epoch 8/10
373/373 - 76s - loss: 0.0012 - accuracy: 1.0000 - val_loss: 3.4144 - val_accuracy: 0.4312
Epoch 9/10
373/373 - 77s - loss: 7.5812e-04 - accuracy: 1.0000 - val_loss: 3.4770 - val_accuracy: 0.4312
Epoch 10/10
373/373 - 77s - loss: 5.3013e-04 - accuracy: 1.0000 - val_loss: 3.5489 - val_accuracy: 0.4355
Es ist wichtig, ein Overfitting (Overfitting) zu vermeiden, daher muss oft mit einer nicht sehr großen Anzahl von Stufen gearbeitet werden.
ID:(13758, 0)
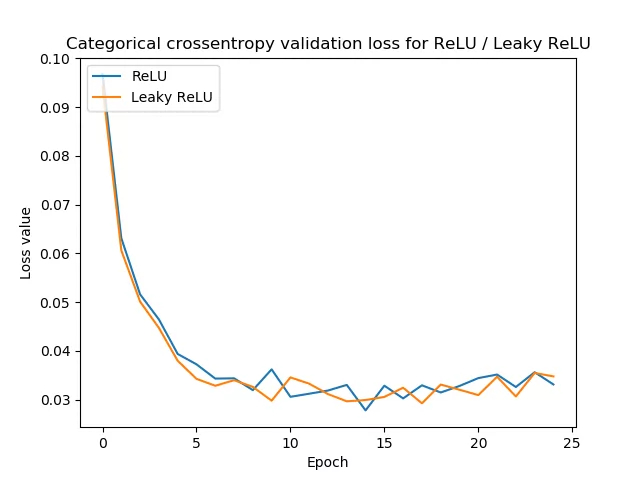
Genauigkeit
Bild
Einer der Faktoren zur Überwachung der Modellqualität ergibt sich aus der Beobachtung der Präzision gemäß der Anzahl der Iterationen (epochs):
ID:(13790, 0)
Modelle speichern
Bild
Um ein Modell zu speichern, führen Sie den Befehl save aus:
# almacenar modelos
directory = 'F:/go/face_scrapper/faces/base_model_20210721'
base_model.save('F:/go/face_scrapper/faces/base_model_20210721')
INFO:tensorflow:Assets written to: F:/go/face_scrapper/faces/base_model_20210721\assetsmit dem ein Ordner mit dem Namen des Verzeichnisses, der Modelldatei und der variables und assets erstellt wird:
ID:(13797, 0)
Modelle laden
Beschreibung
Um ein Modell zu speichern, führen Sie den Befehl save aus:
# Modelle laden directory = 'F:/go/face_scrapper/faces/base_model_20210721' new_model = tf.keras.models.load_model(directory)
ID:(13798, 0)