
Model of estimating ages
Image 
One of the models to study faces is Large Scale Face Dataset (UTKFace)
Webpage: UTKFace
# setup
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
import os
from tqdm import tqdm
# import data
df = pd.read_csv('../../tensorflow_datasets/utkface/extracted_info.csv')
df.dropna(inplace=True)
df = df[df['Age'] <= 90]
df = df[df['Age'] >= 0]
df = df.reset_index()
df['Name'] = df['Name'].apply(lambda x: '../../tensorflow_datasets/utkface/UTKFace/' + str(x))
num_classes = len(df['Age'].unique())
df.head()

ID:(13810, 0)
Prepare libraries
Description
To build the model we import the following libraries and define a routine to display the images:
import tensorflow as tf import keras from keras.preprocessing import image from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint,EarlyStopping from keras.layers import Dense, Activation, Dropout, Flatten, Input, Convolution2D, ZeroPadding2D, MaxPooling2D, Activation from keras.layers import Conv2D, AveragePooling2D from keras.models import Model, Sequential from sklearn.model_selection import train_test_split from keras import metrics from keras.models import model_from_json import matplotlib.pyplot as plt
ID:(13794, 0)
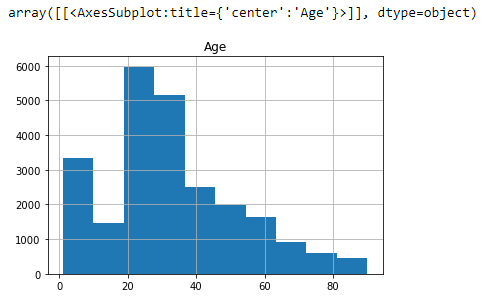
Statistics of the ages of the sample
Description
Statistics of the ages of the sample
# age statistics
df.hist('Age')
ID:(13795, 0)
Re-normalize age
Description
As age is indicated in years, the lowest value is 1. However, the process has greater reliability if the scale begins at 0, so the age is renormalized by subtracting one:
# age statistics
df.hist('Age')

ID:(13812, 0)
Information structure for training and testing
Description
Structure the information for training and testing
# assignment of variables
df_data = df.Name
y_data = df.Age
y2_data = df.Gender
# form array
X_train, X_test, y_train, y_test = train_test_split(df_data, y_data, test_size=0.20, random_state=40)
# show data
d = {'Name':X_train,'Age':y_train}
df_train = pd.concat(d,axis=1)
df_train.head(3)
ID:(13801, 0)
Information structure to train and validate
Description
Information structure to train and validate
# assignment of variables
df_data = df_train.Name
y_data = df_train.Age
y2_data = df.Gender
# form array
X_train, X_val, y_train, y_val = train_test_split(df_data, y_data, test_size=0.1, random_state=42)
# show data
d = {'Name':X_train,'Age':y_train}
train = pd.concat(d,axis=1)
train.head(3)
ID:(13802, 0)
Image processing
Description
The images must be processed to develop the learning process:
# convert age to string
train['Age'] = train['Age'].astype('str')
df_test['Age'] = df_test['Age'].astype('str')
val['Age'] = val['Age'].astype('str')
# process images
batch = 512
train_gen = ImageDataGenerator(rescale=1./255)
test_gen = ImageDataGenerator(rescale=1./255)
train_data = train_gen.flow_from_dataframe(dataframe = train,
#directory = train_folder,
x_col = 'Name',
y_col = 'Age', seed = 42,
batch_size = batch,
shuffle = True,
class_mode='sparse',
target_size = (224, 224))
test_data = test_gen.flow_from_dataframe(dataframe = df_test,
#directory = test_folder,
x_col = 'Name',
y_col = 'Age',
batch_size = batch,
shuffle = True,
class_mode='sparse',
target_size = (224, 224))
val_data = train_gen.flow_from_dataframe(dataframe = val,
#directory = train_folder,
x_col = 'Name',
y_col = 'Age', seed = 42,
batch_size = batch,
shuffle = True,
class_mode='sparse',
target_size = (224, 224))
ID:(13796, 0)
Build sequential model
Description
To assemble the model you can run
# define model
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(224,224, 3)))
model.add(Convolution2D(64, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Convolution2D(4096, (7, 7), activation='relu'))
model.add(Dropout(0.5))
model.add(Convolution2D(4096, (1, 1), activation='relu'))
model.add(Dropout(0.5))
model.add(Convolution2D(2622, (1, 1)))
model.add(Flatten())
model.add(Activation('softmax'))
# load weights
model.load_weights('../../tensorflow_datasets/utkface/vgg_face_weights.h5')
# block first layers
for layer in model.layers[:-6]:
layer.trainable = False
ID:(13803, 0)
Form predictive model and assemble
Description
Forecast layers are assembled and assembled with the base model:
# build prediction section
base_model_output = Convolution2D(num_classes, (1, 1), name='predictions')(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation('softmax')(base_model_output)
# ensamble age model
age_model = Model(inputs=model.input, outputs=base_model_output)
age_model
ID:(13813, 0)
Dataformat for train, validate y test
Description
To show the model is run summary:
# show structure age_model.summary()
Model: 'sequential'
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_45 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
conv2d_46 (Conv2D) (None, 28, 28, 32) 9248
_________________________________________________________________
max_pooling2d_18 (MaxPooling (None, 14, 14, 32) 0
_________________________________________________________________
dropout_27 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_47 (Conv2D) (None, 12, 12, 64) 18496
_________________________________________________________________
conv2d_48 (Conv2D) (None, 10, 10, 64) 36928
_________________________________________________________________
max_pooling2d_19 (MaxPooling (None, 5, 5, 64) 0
_________________________________________________________________
dropout_28 (Dropout) (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_49 (Conv2D) (None, 3, 3, 84) 48468
_________________________________________________________________
dropout_29 (Dropout) (None, 3, 3, 84) 0
_________________________________________________________________
flatten_9 (Flatten) (None, 756) 0
_________________________________________________________________
dense_9 (Dense) (None, 64) 48448
_________________________________________________________________
age_out (Dense) (None, 1) 65
=================================================================
Total params: 162,549
Trainable params: 162,549
Non-trainable params: 0
_________________________________________________________________
ID:(13804, 0)
Form model
Description
Form model:
age_model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True)
, optimizer=keras.optimizers.Adam()
, metrics=['accuracy']
)
checkpointer = ModelCheckpoint(
filepath='classification_age_model_utk.hdf5'
, monitor = 'val_loss'
, verbose=1
, save_best_only=True
, mode = 'auto'
)
target = df['Age'].values
target_classes = keras.utils.to_categorical(target, num_classes)
callback = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3)
ID:(13800, 0)
Running training
Description
To perform the training, you run:
history_2 = age_model.fit(
train_data,
validation_data=val_data,
epochs= 10,
callbacks = [checkpointer],
shuffle=False
)
eff_epochs_2 = len(history_2.history['loss'])Getting
Epoch 1/200
67/67 [==============================] - 15s 215ms/step - loss: 22.6157 - val_loss: 18.4468
Epoch 2/200
67/67 [==============================] - 14s 206ms/step - loss: 15.1609 - val_loss: 16.1411
Epoch 3/200
67/67 [==============================] - 14s 203ms/step - loss: 13.2656 - val_loss: 11.5077
Epoch 4/200
67/67 [==============================] - 14s 203ms/step - loss: 11.9682 - val_loss: 15.2756
Epoch 5/200
67/67 [==============================] - 14s 205ms/step - loss: 11.3574 - val_loss: 10.7042
Epoch 6/200
67/67 [==============================] - 14s 206ms/step - loss: 10.3004 - val_loss: 15.9495
Epoch 7/200
67/67 [==============================] - 14s 205ms/step - loss: 10.3693 - val_loss: 9.1207
Epoch 8/200
67/67 [==============================] - 14s 206ms/step - loss: 9.6405 - val_loss: 12.4468
Epoch 9/200
67/67 [==============================] - 14s 205ms/step - loss: 9.5810 - val_loss: 11.9415
Epoch 10/200
67/67 [==============================] - 14s 208ms/step - loss: 9.7127 - val_loss: 10.0224
Epoch 11/200
67/67 [==============================] - 14s 207ms/step - loss: 9.0834 - val_loss: 12.9822
Epoch 12/200
67/67 [==============================] - 14s 205ms/step - loss: 9.1098 - val_loss: 11.2629
ID:(13805, 0)
Run validation
Description
Para evaluar se corre la validación:
B = age_model.predict(test_data) output_indexes = np.array([i for i in range(0, num_classes)]) apparent_predictions = np.sum(B * output_indexes, axis = 1)
ID:(13806, 0)
Consult a predicted case
Description
To review the development, you can call any of the records and check the estimated and real age:
df_test['Weighted_Avg'] = apparent_predictions
argmax = []
for p in B:
predm = np.argmax(p)
argmax.append(predm)
df_test['ArgMax'] = argmax
df_test.to_csv('Final__wtd_avg')
ID:(13807, 0)
Store models
Description
To store a model, execute the save command:
# almacenar modelos directory = 'F:/go/face_scrapper/faces/age_model_20210723' age_model.save(directory)
INFO:tensorflow:Assets written to: F:/go/face_scrapper/faces/age_model_20210723\assets
ID:(13811, 0)